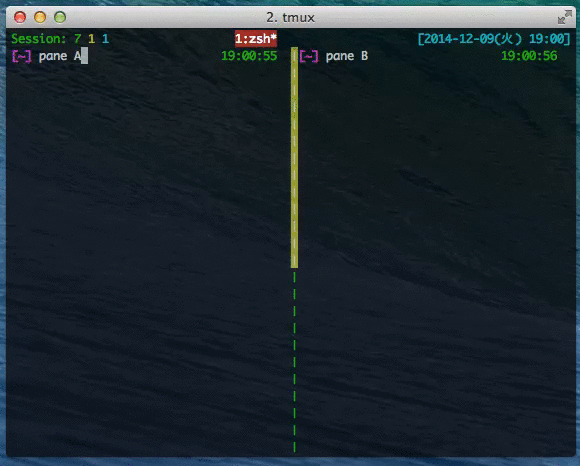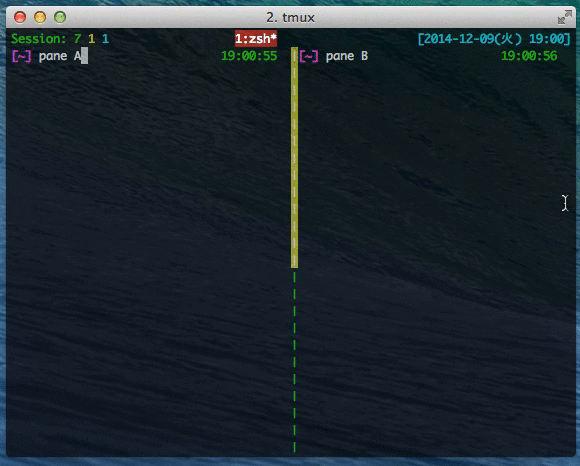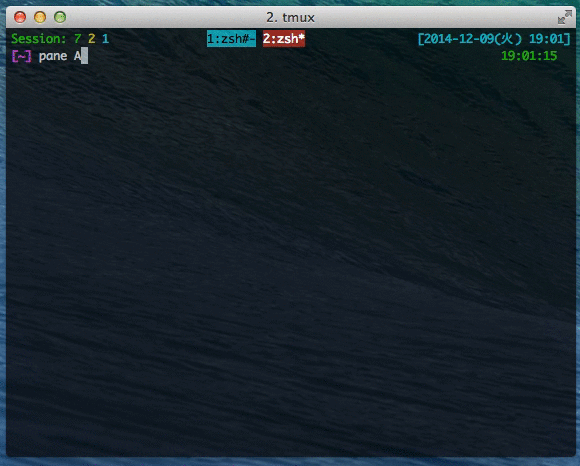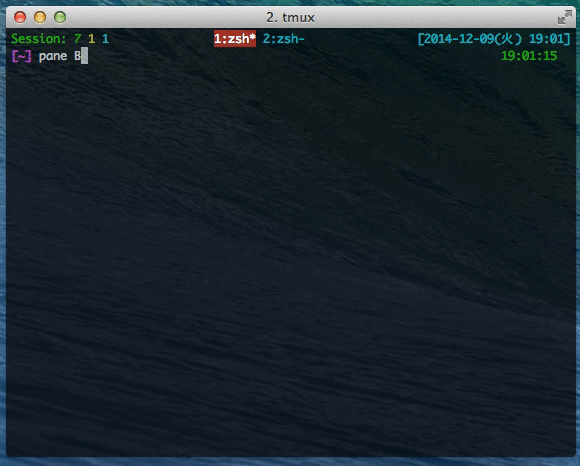
(tmux) ペインを独立したウィンドウに変える
tmux を使っているとペインが増えまくってうざくなることはままあると思う。
そういうときには、ペインをウィンドウとして独立させてしまってスッキリしたらいいと思う。
<prefix> + ! でカレントペインがウィンドウとして独立します。便利です。
BigQueryのunixtimeなカラムをdateに変換する
3号です。ログをBigQueryにつっこむのが流行ってます。
で、timeってカラムがunixtimestampだったとして、XX時〜YY時までのアクセスを抽出したいとします。こんな感じになります。
SELECT
*
FROM
DATASET.TABLE
where
time
between
TIMESTAMP_TO_SEC(DATE_ADD(TIMESTAMP("2014-12-04 22:00:00"), -9, "HOUR"))
and
TIMESTAMP_TO_SEC(DATE_ADD(TIMESTAMP("2014-12-05 23:01:00"), -9, "HOUR"))
order by time desc;
time
------------
1417788060
1417788059
1417788058
抽出結果にdatetime型を並記して表示したいときはこんな感じです。
SELECT
SEC_TO_TIMESTAMP(time) as UTC,
FORMAT_UTC_USEC((time + 32400) * 1000000) as JST,
*
FROM
DATASET.TABLE
where
time
between
TIMESTAMP_TO_SEC(DATE_ADD(TIMESTAMP("2014-12-04 22:00:00"), -9, "HOUR"))
and
TIMESTAMP_TO_SEC(DATE_ADD(TIMESTAMP("2014-12-05 23:01:00"), -9, "HOUR"))
order by time desc;
UTC JST time
------------------------------------------------------------------------
2014-12-05 14:01:00 UTC 2014-12-05 23:01:00.000000 1417788060
2014-12-05 14:00:59 UTC 2014-12-05 23:00:59.000000 1417788059
2014-12-05 14:00:58 UTC 2014-12-05 23:00:58.000000 1417788058
「現在時刻から一分以内」とかだとこんな感じ。
SELECT
SEC_TO_TIMESTAMP(time) as UTC,
FORMAT_UTC_USEC((time + 32400) * 1000000) as JST,
*
FROM
DATASET.TABLE
where
time
between
TIMESTAMP_TO_SEC(DATE_ADD(CURRENT_TIMESTAMP(), -1, 'MINUTE'))
and
TIMESTAMP_TO_SEC(CURRENT_TIMESTAMP())
order by time desc;
そんな感じ。
lessの--no-initオプション
lessで閲覧を終了する時に画面がクリアされてしまうと、途中まで見てたヤツをコピペしたい時に不便な場合に--no-init (-X)を付けておくと便利だよねという話。
毎回指定するのが面倒な場合は環境変数LESSに指定するよう各shellのrcに書いておくと吉
俺とおまえとperlワンライナー
※7号の『俺とおまえとawk』にはてブがいっぱいついて羨ましかったので、丸パクしたのっかりエントリです。
「EFK (Elasticsearch + Fluentd + Kibana) なんて甘えですよ、漢は黙って perl | sort | uniq -c ですよ」と誰かが言ってたような言ってなかったような気がするのでログさらう時に自分がよく使う perl 芸について書きます。
想定データサンプル
こんなフォーマットで出る TSV 形式の Web アプリケーションログがあったとします。[TAB] はタブ文字です。
時間[TAB]ステータス[TAB]HTTPメソッド[TAB]URI[TAB]リクエストタイム
例えばこんな感じです。このログを perl 芸で処理していきます。
access.log
2014-12-05 12:00:00[TAB]200[TAB]GET[TAB]/api/v1/ping[TAB]0.017832 2014-12-05 12:00:01[TAB]200[TAB]POST[TAB]/api/v1/auth[TAB]1.001628 2014-12-05 12:10:00[TAB]404[TAB]GET[TAB]/favicon.ico[TAB]0.017832 2014-12-05 12:10:01[TAB]500[TAB]POST[TAB]/api/v1/login[TAB]5.00003
1分あたりアクセス量を調べる
1分あたりのアクセス量はこんなかんじで調べられるでしょう。
$ perl -nale 'print $F[1]' access.log | perl -F: -nale 'print "$F[0]:$F[1]"' | sort | uniq -c 2 12:00 2 12:10
解説しておくと、最初の perl で時刻フィールドを抜き出しています。
$ perl -nale 'print $F[1]' access.log 12:00:00 12:00:01 12:10:00 12:10:01
aオプションでデフォルトの空白文字、タブ文字を区切り文字として、@F配列に各フィールドの値がセットされます。
print $F[1] のようにして第2フィールドを print しています。今回の場合は時刻のフィールドが出力されます。
※全体の行テキストは$_に格納されます。
パイプでつなげた次の perl で「時:分:秒」を「時:分」に変換しています。 -F オプションを使って区切り文字を : に変更し、第1フィールド(時)、:、第2フィールド(分) を print しています。
$ perl -nale 'print $F[1]' access.log | perl -F: -nale 'print "$F[0]:$F[1]"' 12:00 12:00 12:10 12:10
あとは慣用句と言っても良い sort | uniq -c に渡して、ユニークな値の数をカウントして出力しています。
$ perl -nale 'print $F[1]' access.log | perl -F: -nale 'print "$F[0]:$F[1]"' | sort | uniq -c 2 12:00 2 12:10
ちなみに、上の例では perl を2回使いましたが、perl には substr 関数なんかもあったりするので、以下のようにすると1発で書けたりもします。
使い捨てワンライナーなので、覚えやすい方を使えば良いかと思います。
$ perl -nale 'print substr($F[1], 0, 5)' access.log 12:00 12:00 12:10 12:10
ちなみに自分は正規表現で抜き出す事が多いです。
$ perl -nale '/ (\d\d:\d\d):/;print $1' access.log 12:00 12:00 12:10 12:10
慣れるとApacheのデフォルトフォーマットでも、かなりの精度で必要な値を抜き出せるようになります。
$ head -1 apache_access.log 66.249.71.229 - - [06/Dec/2014:04:04:58 +0900] "GET /robots.txt HTTP/1.1" 200 202 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)" "-" $ perl -nale '/2014:(\d\d:\d\d):.* "GET (\S+)/;print "$1 $2"' apache_access.log 04:04 /robots.txt 04:04 /index.html 05:15 /blog/?category=1
1秒以上時間がかかっているアクセスをリストアップする
今回のログフォーマットでは、一番最後のフィールドがリクエストタイムでした。 一番最後のフィールドは $F[-1] で指定することができます。
$ perl -nale 'print $F[-1]' access.log 0.017832 1.001628 0.017832 5.00003
で、そのフィールドに条件を指定して、1秒以上時間がかかっている行のみをif文で絞り混んでみます。
$ perl -nale 'print if $F[-1] > 1' access.log 2014-12-05 12:00:01 200 POST /api/v1/auth 1.001628 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
もう少し複雑な処理を書く場合は、or next等でその行の処理をスキップするのもいいかもですね。
$ perl -nale '$F[-1] > 1 or next;print' access.log 2014-12-05 12:00:01 200 POST /api/v1/auth 1.001628 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
5xx ステータスコードのアクセスをリストアップする
ステータスコード 500 の行を抜き出すには次のようにすればよいでしょう。
$ perl -nale 'print if $F[2] == 500' access.log 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
正規表現を使うこともできて、5xx な行を抜き出したい場合には次のようにすればよいです。
$ perl -nale 'print if $F[2] =~ /^5/' access.log 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
こちらでも、print $F[フィールド番号] とすれば指定したフィールドだけ出力させることができます。
$ perl -nale 'print $F[4] if $F[2] =~ /^5/' access.log /api/v1/login
おまけ:正規表現マッチはフィールドを指定しない場合、行全体($_) に対する正規表現マッチ($_ =~ /正規表現/)となるので、以下のように書くと grep のような効果を出せます。
$ perl -nale 'print $F[4] if /500/' access.log 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
合計リクエストタイムを求める
アクセスログのうち合計リクエストタイムを求めるには、ちょっとめんどくさいですが、次のようにします。
$ perl -nale 'BEGIN{$sum=0};$sum += $F[-1];END{print $sum}' access.log
6.03732
変数はデフォルトで 0 に初期化されるので、BEGIN{$sum=0} は省略可能です。
最大値を求めたい場合は、
$ perl -nale '$max = $F[-1] if $F[-1] > $max;END{print $max}' access.log
5.00003
とかですかね。めんどくさいですが、まぁそんなもんですね。
特定の条件ごとのアクセス数、平均応答速度、合計応答速度を求める
例として、1分ごとのアクセス数、平均応答速度、合計応答速度を出力してみます。
複雑な例ですが、このぐらいの処理がサクッと書けると各種調査、障害時の切り分けにかなり役立ちます。
$ perl -nale '/ (\d\d:\d\d):/;$cnt{$1}++;$sum{$1}+=$F[-1];END{print join " ", ($_, $cnt{$_}, $sum{$_}/$cnt{$_}, $sum{$_}) for sort keys %cnt}' access.log
12:00 2 0.50973 1.01946
12:10 2 2.508931 5.017862
%cnt、%sumに抽出した条件(今回は時間)ごとのアクセス数と応答速度をカウントアップしていき、最後にまとめて出力しています。
LTSV なログを処理する
最近は LTSV フォーマットが人気です。
例えば、次のような LTSV ログがあったとして、
time:2014-08-13T14:10:10Z[TAB]status:200 time:2014-08-13T14:10:12Z[TAB]status:500
status フィールドの値だけを perl で抜き出そうとするとこんなかんじになるでしょうか。
$ perl -F'\t' -nale 'for(@F){($k, $v) = split(":", $_, 2);$h{$k} = $v};print $h{status}' ltsv.log
200
500
『LTSVログをパースする最強のワンライナー集』には以下のような記法が紹介されています。
$ perl -F'\t' -nale '%h=map{split/:/,$_,2}@F;print $h{status}' ltsv.log
200
500
番外編:sedの代わりに使う
nオプションの代わりにpオプションを使って、引数にs式を渡すとsedと同じように使えます。
$ perl -pe 's/\tstatus:\d+$//' ltsv.log time:2014-08-13T14:10:10Z time:2014-08-13T14:10:12Z
perl互換の正規表現が使えるので非常に便利です。 iオプションなども同じように使えます。
おわりに
いやー、perl サイコーですね。ログを手打ちで perl コマンド打って集計するなんて幸せすぎて泣けてきますね。Enjoy happy perl life!
俺とおまえとawk
「EFK (Elasticsearch + Fluentd + Kibana) なんて甘えですよ、漢は黙って awk | sort | uniq -c ですよ」と誰かが言ってたような言ってなかったような気がするのでログさらう時に自分がよく使う awk 芸について書きます。
想定データサンプル
こんなフォーマットで出る TSV 形式の Web アプリケーションログがあったとします。[TAB] はタブ文字です。
時間[TAB]ステータス[TAB]HTTPメソッド[TAB]URI[TAB]リクエストタイム
例えばこんな感じです。このログを awk 芸で処理していきます。
access.log
2014-12-05 12:00:00[TAB]200[TAB]GET[TAB]/api/v1/ping[TAB]0.017832 2014-12-05 12:00:01[TAB]200[TAB]POST[TAB]/api/v1/auth[TAB]1.001628 2014-12-05 12:10:00[TAB]404[TAB]GET[TAB]/favicon.ico[TAB]0.017832 2014-12-05 12:10:01[TAB]500[TAB]POST[TAB]/api/v1/login[TAB]5.00003
1分あたりアクセス量を調べる
1分あたりのアクセス量はこんなかんじで調べられるでしょう。
$ awk '{print $2}' access.log | awk -F: '{print $1 ":" $2}' | sort | uniq -c
2 12:00
2 12:10
解説しておくと、最初の awk で時刻フィールドを抜き出しています。
$ awk '{print $2}' access.log
12:00:00
12:00:01
12:10:00
12:10:01
デフォルトの空白文字、タブ文字を区切り文字として、
{print $2} のようにして第2フィールドを print しています。今回の場合は時刻のフィールドが出力されます。
パイプでつなげた次の awk で「時:分:秒」を「時:分」に変換しています。 -F オプションを使って区切り文字を : に変更し、第1フィールド(時)、:、第2フィールド(分) を print しています。
$ awk '{print $2}' access.log | awk -F: '{print $1 ":" $2}'
12:00
12:00
12:10
12:10
あとは慣用句と言っても良い sort | uniq -c に渡して、ユニークな値の数をカウントして出力しています。
$ awk '{print $2}' access.log | awk -F: '{print $1 ":" $2}' | sort | uniq -c
2 12:00
2 12:10
ちなみに、上の例では awk を2回使いましたが、awk には substr 関数なんかもあったりするので、以下のようにすると1発で書けたりもします。
使い捨てワンライナーなので、覚えやすい方を使えば良いかと思います。
$ awk '{print substr($2,1,5)}' access.log
12:00
12:00
12:10
12:10
1秒以上時間がかかっているアクセスをリストアップする
今回のログフォーマットでは、一番最後のフィールドがリクエストタイムでした。 一番最後のフィールドは $NF で指定することができます。
$ awk '{print $NF}' access.log
0.017832
1.001628
0.017832
5.00003
で、そのフィールドに条件を指定して、1秒以上時間がかかっている行のみに絞り混んでみます。次のようにします。
$ awk '$NF > 1.0' access.log 2014-12-05 12:00:01 200 POST /api/v1/auth 1.001628 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
これは以下のコマンドと同等です。
{} を省略した場合、デフォルトで {print $0} (全フィールドの表示) になります。
$ awk '$NF > 1.0 {print $0}' access.log
2014-12-05 12:00:01 200 POST /api/v1/auth 1.001628
2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
おまけ:一番最後から1個前のフィールドは $(NF-1) で指定することができます。
2個前なら $(NF-2) ですね。例えば、こんなかんじでつかいます。
$ awk '$NF > 1.0 {print $(NF-1)}' access.log
/api/v1/auth
/api/v1/login
5xx ステータスコードのアクセスをリストアップする
ステータスコード 500 の行を抜き出すには次のようにすればよいでしょう。
$ awk '$3 == 500' access.log 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
正規表現を使うこともできて、5xx な行を抜き出したい場合には次のようにすればよいです。
$ awk '$3 ~ /^5/' access.log 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
こちらでも、{print フィールド番号} とすれば指定したフィールドだけ出力させることができます。
$ awk '$3 ~ /^5/ {print $5}' access.log
/api/v1/login
おまけ:正規表現マッチはフィールドを指定しない場合、行全体($0) に対する正規表現マッチ($0 ~ /正規表現/)となるので、以下のように書くと grep のような効果を出せます。
$ awk '/500/' access.log 2014-12-05 12:10:01 500 POST /api/v1/login 5.00003
合計リクエストタイムを求める
アクセスログのうち合計リクエストタイムを求めるには、ちょっとめんどくさいですが、次のようにします。
$ awk 'BEGIN{sum=0}{sum+=$NF}END{print sum}' access.log
6.03732
変数はデフォルトで 0 に初期化されるので、BEGIN{sum=0} は省略可能です。
最大値を求めたい場合は、
$ awk '{if($NF > max)max=$NF}END{print max}' access.log
5.00003
とかですかね。めんどくさいですが、まぁそんなもんですね。
LTSV なログを処理する
最近は LTSV フォーマットが人気ですが、ラベル:値 のフィールドを分離して 値 だけを取り出した TSV 形式に変換しないと awk では扱いづらいです。例えば、次のような LTSV ログがあったとして、
time:2014-08-13T14:10:10Z[TAB]status:200 time:2014-08-13T14:10:12Z[TAB]status:500
status フィールドの値だけを awk で抜き出そうとするとこんなかんじになるでしょうか。 面倒ですね。
$ awk -F\t '{split($2, status, ":"); print status[2]}' ltsv.log
200
500
awk でも扱いやすくするために皆さん、色々試行錯誤されているようです。
- awkとシェルでLTSVの取り扱いを簡単にするフィルタを書いてみた
- LTSV のログを jq でフィルタする
- lltsv という LTSV の特定キーだけ取り出す golang アプリケーションを書いた
こちらの lltsv というツールを使うと
$ lltsv -k time,status -K ltsv.log 2014-08-13T14:10:10Z 200 2014-08-13T14:10:12Z 500
のように値を取り出す事ができるので、そのまま awk につなげて
$ lltsv -k time,status -K ltsv.log | awk '$2 == 500' 2014-08-13T14:10:12Z 500
のように扱えるようです。便利っぽいですね。
おわりに
いやー、awk サイコーですね。ログを手打ちで awk コマンド打って集計するなんて幸せすぎて泣けてきますね。Enjoy happy awk life!
追記: awk 芸の高みへ
「統計屋のためのAWK入門」の記事が大変参考になるので物足りない方は読むと良いと思いますね!
GoConveyでerror型をテストする時に気をつける事
こんにちは。何号だっけ・・・。
Goでアプリを書いている時にテストでGoConvey
smartystreets/goconvey · GitHub
を使っているんですが、error型の比較時に軽くハマったのでメモです。
単純な文字列比較であれば
So(hogehoge, ShouldEqual, "fugafuga")
の様に比較出来るのですが、error型でエラーメッセージが入っているからそれを比較しようと
So(errorObject, ShouldEqual, "error message")
とやると、実際にerrorObjectの中に"error message"が入っていて文字列として等価でもgo test実行するとこんな感じの
Failures: * /tmp/test.go Line 4: Expected: 'error message' Actual: 'error message' (Should be equal)
というエラーになってしまいます。
じゃあ、比較する側もerror型にしてみれば良いだろ、と
So(errorObject, ShouldEqual, errors.New("error message"))
とやってもこれもダメです。
ではどうすれば良いのかというと
errorMessage := errors.New("error message")
So(errorObject.Error(), ShouldEqual, errorMessage.Error())
と記述する事で比較出来ました。おそらく初めの比較はerror型とstringの比較になってしまっているのかなと思いますが、2個めの比較はおそらくerror型ではあるが同一オブジェクトでは無いという判定になっていると思います。3個目は出力された物としてお互い比較が出来ているから想定しているエラーメッセージのテストが出来ました。
追記 自分で書いておきながら
So(errorObject.Error(), ShouldEqual, "error message")
を試していませんでしたが、これもpassしました。こっちの方が簡潔ですね。